This project is kept for historical purposes, if you’re new here you may want to check out upper.io/db.v2 instead.
db.v1is deprecated and no new features will be added, only security issues will be patched, we recommend you to migrate from db.v1 to db.v2.
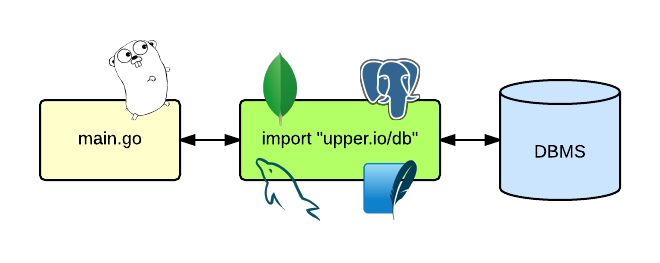
The upper.io/db.v1 package for Go provides a common interface for
interacting with different data sources using adapters that wrap mature
database drivers.
import(
// The db package.
"upper.io/db.v1"
// The PostgreSQL adapter.
"upper.io/db.v1/postgresql"
)
As of today, upper.io/db.v1 supports the MySQL, PostgreSQL,
SQLite and QL database management systems and provides partial
support for MongoDB.
This is the documentation site of upper.io/db.v1, if you’re looking for the
source code repository you may find it at github.
upper.io/db.v1 is proudly sponsored by pressly.com.

upper.io/db.v1upper.io/db.v1 an ORM?Yes, a very basic one. upper.io/db.v1 is not tyrannical in the sense it
does not impose any restrictions or conventions on how structures should be
written nor provides automatic table creation, migrations, index management or
any additional magic that the developer probably knows better; it just
abstracts the most common operations you may need when working with database
management systems and lets you focus on designing the complex tasks. Whenever
you need to do some complicated database query you’ll have to do it by
hand, so having a good understanding of the database you’re working on is
essential.
upper.io/db.v1?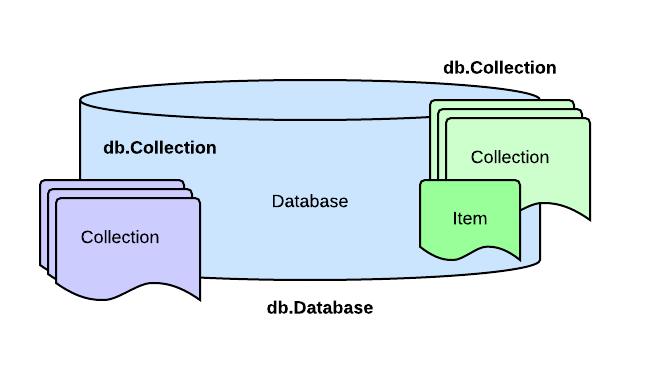
The database management systems (DBMS) provides access to sets of collections
of items which are known as databases. A database is represented as a
db.Database interface, collections (SQL tables) are represented as
db.Collection interfaces and items may be represented as user-defined
structs or maps of type map[string]interface{}. We recommend you using
structs as they provide a more solid framework to work on, maps may come in
handly for quick hacks when some flexibility is needed.
This is a syntax example in which col is a value that satisfies
db.Collection, person is an array of an user-defined struct and res
satisfies db.Result:
// Array of people.
var people []Person
// A subset of items with property name = "Max".
res = col.Find(db.Cond{"name": "Max"})
// Mapping items into the people array.
err = res.All(&people)
The above example picks a set from the collection that satisfies the condition
property “name” equals “Max”, represented by db.Cond{"name": "Max"},
whether these properties are SQL columns or MongoDB fields.
The main concept behind upper.io/db.v1 centers around subsets of items from a
collection, a collection is a set of items that have properties, these
properties may be fixed (SQL tables) or flexible (NoSQL collections).
Once you have a collection reference (db.Collection) you can use the
Find() method on it to delimit the subset of items of the collection to work
with. If no condition is given, all items of the collection will be selected.
Conditions are passed to Find() as values of type db.Cond,
db.And, db.Or, db.Constrainer or db.Raw.
The Find() method returns a db.Result interface on which you may
execute a variety of methods, such as One(), All(), Count(), Remove(),
Update() and so on.
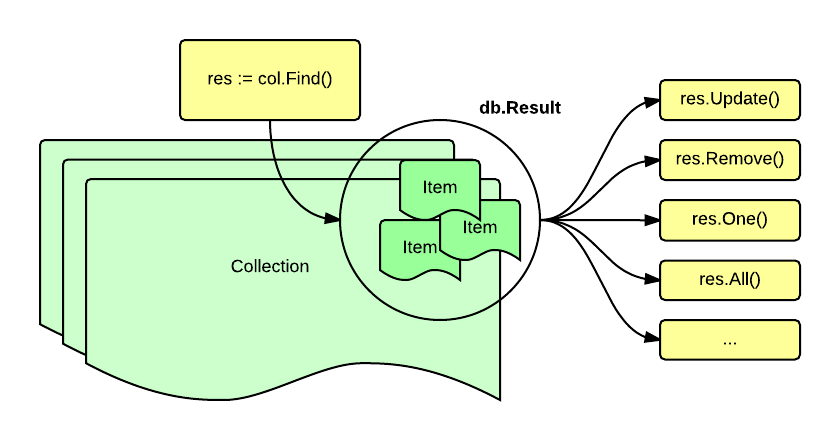
This is essentially different from SQL and feels a lot like NoSQL in the sense that a condition must be set in order to choose a subset of items before doing something with them.
The upper.io/db.v1 package depends on the Go compiler and tools. Version
1.1+ is preferred since the underlying mgo driver for the mongo adapter
depends on a method (reflect.Value.Convert()) introduced in go1.1. However,
using a previous Go version (down to go1.0.1) could still be possible with
other adapters.
In order to use go get to fetch and install Go packages, you’ll also
need the git version control system. Please refer to the git project
site for specific instructions on how to install it in your operating system.
go getOnce you’ve installed Go, you will be able to download and install the
upper.io/db.v1 package using go get:
go get upper.io/db.v1
Note: If the go get program fails with something like:
package upper.io/db.v1: exec: "git": executable file not found in $PATH
it means that a required program is missing, git in this case. To fix this
error install the missing application and try again.
Installing the main package just provides base structures and interfaces but in order to actually communicate with a database you’ll also need a database adapter.
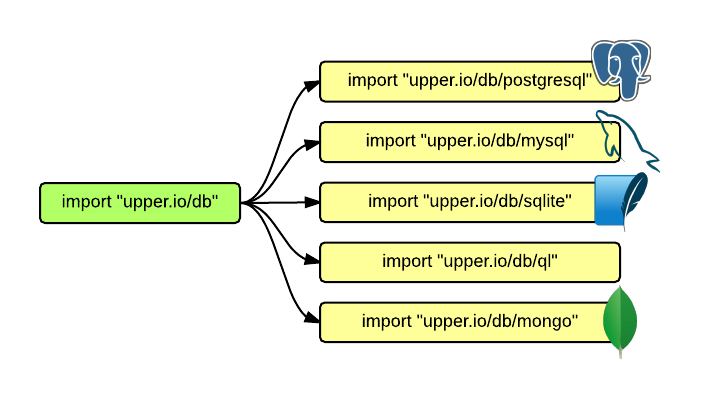
Here’s a list of available database adapters. Look into the adapter’s link to see installation instructions that are specific to each adapter.
The following part is optional, in this example you’ll learn how to use the SQLite adapter to open an existent SQLite database.
Open a terminal and check if the sqlite3 command is installed. If the program
is missing install it like this:
# Installing sqlite3 in Debian
sudo apt-get install sqlite3 -y
Then, run the sqlite3 command and create a test.db database:
sqlite3 test.db
The sqlite3 program will welcome you with a prompt:
sqlite>
From within the sqlite3 prompt, create a demo table:
CREATE TABLE demo (
first_name VARCHAR(80),
last_name VARCHAR(80),
bio TEXT
);
After creating the table, type .exit to end the sqlite3 session.
sqlite> .exit
Create a main.go file and import both the db package (upper.io/db.v1) and
the SQLite adapter (upper.io/db.v1/sqlite):
// main.go
package main
import (
"upper.io/db.v1"
"upper.io/db.v1/sqlite"
)
Configure the database credentials using the adapter’s own
db.ConnectionURL struct. In this case we’ll be using the
sqlite.ConnectionURL:
type ConnectionURL struct {
Database string
Options map[string]string
}
Use sqlite.ConnectionURL to configure the access to your database:
// main.go
var settings = sqlite.ConnectionURL{
// A SQLite database is a plain file.
Database: `/path/to/example.db`,
}
After configuring the database settings create a main() function and use
db.Open() to open the database.
// Using db.Open() to open the sqlite database
// specified by the settings variable.
sess, err = db.Open(sqlite.Adapter, settings)
The sess variable is your database session, you may now use any
db.Database method on this value.
Collections are sets of items of the same class. SQL tables and NoSQL
collections are both known as just “collections” within the upper.io/db.v1
context.
In order to use and query collections you’ll need a collection reference, use
the db.Database.Collection() method on the previously defined sess variable
in order to get a collection reference:
// Pass the table/collection name to get a collection
// reference.
col, err = sess.Collection("demo")
If you want to insert some data into a collection, you need to define a struct that maps properties to collection columns:
// Use the "db" tag to match database column names with Go
// struct property names.
type Demo struct {
FirstName string `db:"first_name"`
LastName string `db:"last_name"`
Bio string `db:"bio,omitempty"`
}
This is how you’d insert a Demo{} value into the col collection:
item = Demo{
"Hayao",
"Miyazaki",
"Japanese film director.",
}
col.Append(item)
Inserting data without defining a struct is possible by mapping columns to values directly:
item = map[string]interface{}{
"first_name": "Hayao",
"last_name": "Miyazaki",
"bio": "Japanese film director.",
}
col.Append(item)
If you have followed the example until here, then you may be able to put together a program that may look like this:
// main.go
package main
import (
"log"
"upper.io/db.v1"
"upper.io/db.v1/sqlite"
)
var settings = sqlite.ConnectionURL{
Database: "test.db",
}
type Demo struct {
FirstName string `db:"first_name"`
LastName string `db:"last_name"`
Bio string `db:"bio"`
}
func main() {
var err error
var sess db.Database
var col db.Collection
sess, err = db.Open(sqlite.Adapter, settings)
if err != nil {
log.Fatal(err)
}
defer sess.Close()
col, err = sess.Collection("demo")
if err != nil {
log.Fatal(err)
}
err = col.Append(Demo{
FirstName: "Hayao",
LastName: "Miyazaki",
Bio: "Japanese film director.",
})
if err != nil {
log.Fatal(err)
}
}
compile and run it:
go build main.go
./main
A new item should be appended to our “demo” table.
Note: upper.io/db.v1 works fine with maps but using structs is the
recommended way for mapping table rows or collection elements into Go values,
as they provide more expressiveness on how columns are actually mapped.
This is the end of the SQLite example but we’ll continue exploring the API.
You can map database column names to struct properties in a similar way the
encoding/json package does.
In this example:
type Foo struct {
// Will match the column named "id".
ID int64
// Will match the column named "title".
Title string
// Will be ignored, as it's not an exported property.
private bool
}
The ID and Title properties begin with an uppercase letter, so they are
exported properties. Exported properties of a struct are mapped to table
columns according to their name (letter case and underscores won’t matter),
while the private property is unexported and will be ignored by
upper.io/db.v1.
upper.io/db.v1 assumes that a property will be matched to one and only one
column, trying to map multiple properties to the same column is currently not
supported.
db tag).If the name of the exported property is different from the name of the column,
you could use a db tag in the property definition to bind it to a custom
column name:
type Foo struct {
ID int64
// Will be mapped to the "foo_title" column.
Title string `db:"foo_title"`
private bool
}
The db tag could be used to pass additional options for properties. You can
specify more than one option by separating them using commas:
type Foo struct {
ID int64
Title string `db:"column,opt1,opt2,..."`
private bool
}
If you’d like to avoid using an exported property in a statement when it’s
empty, you can pass the omitempty option to the db tag, like this:
type Foo struct {
// Will be skipped when ID == 0.
ID int64 `db:"id,omitempty"`
Title string `db:"foo_title"`
private bool
}
If you need to skip an exported property you can set its name to “-” using a
db tag:
type Foo struct {
ID int64
Title string
private bool
IgnoredProperty string `db:"-"`
}
You can have as name properties named "-" as you need:
type Foo struct {
ID int64
Title string
private bool
IgnoredProperty string `db:"-"`
IgnoredProperty1 string `db:"-"`
IgnoredProperty2 string `db:"-"`
}
If you need to embed one struct into another and you’d like the two of them
being considered as if they were part of the same struct (at least on
upper.io/db.v1 context), you can pass the inline option to the property name,
like this:
type Foo struct {
ID int64
Title string `db:"-"`
private bool
}
type Bar struct {
EmbeddedFoo Foo `db:",inline"`
ExtraProperty string `db:"extra_property"`
}
Embedding with inline also works for anonymous properties:
type Foo struct {
ID int64
Title string `db:"-"`
private bool
}
type Bar struct {
Foo `db:",inline"`
ExtraProperty string `db:"extra_property"`
}
An optional db.IDSetter interface that could be satisfied by data structs is defined as follows:
// IDSetter is the interface implemented by structs that can set
// their own ID after calling Append().
type IDSetter interface {
SetID(map[string]interface{}) error
}
Satisfying IDSsetter makes easier grabbing IDs from col.Append() calls and
it also works on tables that support composite keys.
// Defining a Foo struct.
type Foo struct {
ID uint
Bar string
}
// The values map uses all the columns that compose a primary
// index as keys mapped to their new values.
func (f *Foo) SetID(values map[string]interface{}) error {
if valueInterface, ok := values["id"]; ok {
// A conversion from interface{} is required.
f.ID = valueInterface.(int64)
}
return nil
}
func Demo() {
// ...
foo := Foo{
Bar: "Hello!",
}
// Note that were passing a pointer of foo.
if _, err := col.Append(&foo); err != nil {
// Handle error.
}
fmt.Printf("The new ID is: %v\n", foo.ID)
// ...
}
The db.IDSetter interface may work great for tables with multiple keys, but it feels a bit awkward for tables with a single integer key.
In this case, you may want to use the db.Int64IDSetter or the db.Uint64IDSetter interfaces that will send you the ID with type int64 or uint64.
type artistWithInt64Key struct {
id int64
Name string `db:"name"`
}
// This SetID() will be called after a successful Append().
func (artist *artistWithInt64Key) SetID(id int64) error {
artist.id = id
return nil
}
This feature is supported in the PostgreSQL, MySQL and SQLite adapters.
The db.Constrainer interface is intended to be used on db.Find() calls to
let the struct that satisfies the interface constraint itself using a
condition.
// Constrainer is the interface implemented by structs that
// can delimit themselves.
type Constrainer interface {
Constraint() Cond
}
This is an usage example:
// Defining a Foo struct.
type Foo struct {
ID uint
Bar string
}
// Foo will try to constraint itself to all the items that
// satisfy the id = f.ID condition (probably just one, if
// "id" is a primary key).
func (f Foo) Constraint() db.Cond {
cond := db.Cond{
"id": f.ID,
}
return cond
}
func Demo() {
// ...
var foo Foo
// This anonymous Foo{} satisfies [db.Constrainer][24].
res := col.Find(Foo{ID: 42})
// One() will use the contraint already set in place
// by Find() and Foo{}.
if err := res.One(&foo); err != nil {
// Handle error.
}
fmt.Printf("The value of foo is: %v\n", foo)
// ...
}
You can use the db.Collection.Find() to define a result sets.
Result sets can be iterated (db.Collection.Next()), dumped to a pointer
(db.Result.One()) or dumped to a pointer of array of items
(db.Result.All()).
// SELECT * FROM people WHERE last_name = "Miyazaki"
res = col.Find(db.Cond{"last_name": "Miyazaki"})
Once you have a result set (res in this example), you can choose to fetch
results into an array, providing a pointer to an array of structs or maps, as
in the following example.
// Define birthday as an array of Birthday{} and fetch
// the contents of the result set into it using
// `db.Result.All()`.
var birthday []Birthday
err = res.All(&birthday)
Filling an array could be expensive if you’re working with a lot of items, if
you’re working with big result sets looping over one result at a time will
perform better. Use db.Result.Next() to fetch one item at a time:
var birthday Birthday
for {
// Walking over the result set.
err = res.Next(&birthday)
if err == nil {
// No error happened.
} else if err == db.ErrNoMoreRows {
// Natural end of the result set.
break;
} else {
// Another kind of error, should be taken care of.
return res
}
}
// Remember to close the result set when using
// db.Result.Next()
res.Close()
If you need only one element of the result set, the db.Result.One() method
would be better suited for the task.
var birthday Birthday
err = res.One(&birthday)
Once you have a basic understanding of result sets, you can start using conditions, limits and offsets to reduce the amount of items returned in a query.
Use the db.Cond type to define conditions for db.Collection.Find().
type db.Cond map[string]interface{}
// SELECT * FROM users WHERE user_id = 1
res = col.Find(db.Cond{"user_id": 1})
If you want to add multiple conditions just provide more keys to the db.Cond map:
// SELECT * FROM users where user_id = 1
// AND email = "[email protected]"
res = col.Find(db.Cond{
"user_id": 1,
"email": "[email protected]",
})
provided conditions will be grouped under an AND conjunction, by default.
If you want to use the OR disjunction instead, the db.Or type is available.
The following code:
// SELECT * FROM users WHERE
// email = "[email protected]"
// OR email = "[email protected]"
res = col.Find(db.Or{
db.Cond{
"email": "[email protected]",
},
db.Cond{
"email": "[email protected]",
}
})
uses OR disjunction instead of AND.
Complex AND filters can be delimited by the db.And type.
This example:
res = col.Find(db.And{
db.Or{
db.Cond{
"first_name": "Jhon",
},
db.Cond{
"first_name": "John",
},
},
db.Or{
db.Cond{
"last_name": "Smith",
},
db.Cond{
"last_name": "Smiht",
},
},
})
means (first_name = "Jhon" OR first_name = "John") AND (last_name = "Smith" OR
last_name = "Smiht").
A col.Find() instruction returns a db.Result interface, and some methods
of db.Result return the same interface, so they can be called in a
chainable fashion.
This example:
res = col.Find().Skip(10).Limit(8).Sort("-name")
skips ten items, counts up to eight items and sorts the results by name (descendent).
If you want to know how many items does the set hold, use the
db.Result.Count() method:
c, err := res.Count()
this method will ignore Offset and Limit settings, so the returned result
is the total size of the result set.
NULL valuesThe database/sql package provides some special types
(NullBool,
NullFloat64,
NullInt64 and
NullString) that can be used
to represent values than may be NULL at some point.
The postgresql, mysql, sqlite and ql adapters support those special
types and they work as expected:
type TestType struct {
...
salary sql.NullInt64
...
}
The upper.io/db.v1 package provides two special interfaces that can be used to
transform data before saving it into the database and to revert the
transformation when the data is retrieved.
The db.Marshaler interface is defined as:
type Marshaler interface {
MarshalDB() (interface{}, error)
}
The MarshalDB() function should be used to transform the type’s current value
into a format that the database can accept and save.
For instance, if you’d like to save a time.Time data as an unix timestamp
(integer) instead of saving it as an string representation of the date, you
should implement MarshalDB().
The db.Unmarshaler interface is defined as:
type Unmarshaler interface {
UnmarshalDB(interface{}) error
}
If you’d like to transform the stored UNIX timestamp into a time.Time value,
you should implement UnmarshalDB().
The UnmarshalDB() function should be used to transform a value that was
retrieved from the database into a Go type.
The following example defines a timeType struct that can handle dates using the
native time.Time type. These dates are actually stored as integers (UNIX
timestamp). The MarshalDB() and UnmarshalDB() functions work as opposite
transformations.
// Struct for testing marshalling.
type timeType struct {
// Time is handled internally as time.Time but saved
// as an (integer) unix timestamp.
value time.Time
}
// time.Time -> unix timestamp
func (u timeType) MarshalDB() (interface{}, error) {
return u.value.Unix(), nil
}
// Note that we're using *timeType and no timeType.
// unix timestamp -> time.Time
func (u *timeType) UnmarshalDB(v interface{}) error {
var i int
switch t := v.(type) {
case string:
i, _ = strconv.Atoi(t)
default:
return db.ErrUnsupportedValue
}
t := time.Unix(int64(i), 0)
*u = timeType{t}
return nil
}
// struct with a *timeType property.
type birthday struct {
...
BornUT *timeType `db:"born_ut"`
...
}
Note: Currently, marshaling and unmarshaling are only available on the
postgresql, mysql and sqlite adapters.
Result sets are automatically closed after calls to db.Result.All() and
db.Result.One(), but if you’re using db.Result.Next() you must close your
result when you’re done with it:
res.Close()
If you’re not properly closing result sets, you could run into nasty problems with zombie database connections.
Result sets are not only capable of returning items, they can also be used to update or delete all the items that match the given conditions.
If you want to update the whole set of items you can use the
db.Result.Update() method.
res = col.Find(db.Cond{"name": "Old name"})
err = res.Update(map[string]interface{}{
"name": "New name",
})
If you want to delete a set of items, use the db.Result.Remove() method on a
result set.
res = col.Find(db.Cond{"active": false})
res.Remove()
There are many more things you can do with a db.Database reference besides getting a collection.
For example, you could get a list of all collections within the database:
all, err = sess.Collections()
for _, name := range all {
fmt.Printf("Got collection %s.\n", name)
}
If you need to switch databases, you can use the db.Database.Use() method
err = sess.Use("another_database")
You can enable the logging of generated SQL statements and errors to standard
output by using the UPPERIO_DB_DEBUG environment variable:
UPPERIO_DB_DEBUG=1 ./go-program
You can also use this environment variable when running tests.
cd $GOPATH/src/upper.io/db.v1/sqlite
UPPERIO_DB_DEBUG=1 go test
...
2014/06/22 05:15:20
SQL: SELECT "tbl_name" FROM "sqlite_master" WHERE ("type" = 'table')
2014/06/22 05:15:20
SQL: SELECT "tbl_name" FROM "sqlite_master" WHERE ("type" = ? AND "tbl_name" = ?)
ARG: [table artist]
...
You can use the db.Database.Transaction() function to start a transaction (if
the database adapter supports such feature). db.Database.Transaction() will
return a clone of the session (type db.Tx) with two added functions:
db.Tx.Commit() and db.Tx.Rollback() that you can use to save the
transaction or to abort it.
var tx db.Tx
if tx, err = sess.Transaction(); err != nil {
log.Fatal(err)
}
var artist db.Collection
if artist, err = tx.Collection("artist"); err != nil {
log.Fatal(err)
}
if _, err = artist.Append(item); err != nil {
log.Fatal(err)
}
if err = tx.Commit(); err != nil {
log.Fatal(err)
}
Many situations will require you to use methods that are specific to the
underlying driver, for example, if you’re in the need of using the
mgo.Session.Ping method, you
can retrieve the underlying *mgo.Session as an interface{}, cast it with
the appropriate type and use the mgo.Session.Ping() method on it, like this:
drv = sess.Driver().(*mgo.Session)
err = drv.Ping()
This is another example using db.Database.Driver() with a SQL adapter:
drv = sess.Driver().(*sql.DB)
rows, err = drv.Query("SELECT name FROM users WHERE age=?", age)
Sometimes you’ll need to run complex SQL queries with joins and database
specific magic, there is an extra package sqlutil that may come handy in such
situation:
import "upper.io/db.v1/util/sqlutil"
This is an example for sqlutil.FetchRows:
var sess db.Database
var rows *sql.Rows
var err error
var drv *sql.DB
type publication_t struct {
ID int64 `db:"id,omitempty"`
Title string `db:"title"`
AuthorID int64 `db:"author_id"`
}
if sess, err = db.Open(Adapter, settings); err != nil {
t.Fatal(err)
}
defer sess.Close()
drv = sess.Driver().(*sql.DB)
rows, err = drv.Query(`
SELECT
p.id,
p.title AS publication_title,
a.name AS artist_name
FROM
artist AS a,
publication AS p
WHERE
a.id = p.author_id
`)
if err != nil {
t.Fatal(err)
}
var all []publication_t
// Mapping to an array.
if err = sqlutil.FetchRows(rows, &all); err != nil {
t.Fatal(err)
}
if len(all) != 9 {
t.Fatalf("Expecting some rows.")
}
You can also use sqlutil.FetchRow(*sql.Rows, interface{}) for mapping results
obtained from sql.DB.Query() statements to a pointer of a single struct
instead of a pointer to an array of structs. Please note that there is no
support for sql.DB.QueryRow() and that you must provide a *sql.Rows value
to both sqlutil.FetchRow() and sqlutil.FetchRows().
You can see the full method reference for upper.io/db.v1 at godoc.org.
Thanks for taking the time to contribute. There are many ways you can help this project:
The source code page at github includes a nice issue tracker, please use this interface to report bugs.
The source code page at github includes an issue tracker, see the
issues or create one, then create a fork, hack on your fork and when
you’re done create a pull request, so that the code contribution can get
merged into the main package. Note that not all contributions can be merged to
upper.io/db.v1, so please be very explicit on justifying the proposed change and
on explaining how the package users can get the greater benefit from your hack.
There is a special documentation repository at github where you may also file issues. If you find any spot were you would like the documentation to be more descriptive, please open an issue to let us know; and if you’re in the possibility of helping us fixing grammar errors, typos, code examples or even documentation issues, please create a fork, edit the documentation files and then create a pull request, so that the contribution can be merged into the main repository.
The MIT license:
Copyright © 2013-2014 José Carlos Nieto, https://menteslibres.net/xiam
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.